Py with python
The goal of this first notebook is to get you started with setting up your python environment.
The bare minimum required to run this notebook is
- python: the language interpreter
- numpy: a library for multidimensional array and much more
- jupyter: a library that lets you open, edit and run notebooks like this one!
Perhaps the most straightforward way to get started is simply to install the newly developed jupyterlab app. This will have all necessary dependencies installed at this point. Later on you will need to install additionaly packages.
# we tell the interpreter that we will use numpy
import numpy as np
%load_ext autoreload
%autoreload 2
# the following loads my solution file, which you do not have!
# you should comment the following line, or create your solution in solutions/sol_ols.py
%cd ..
import solutions.sol_pi as solution
/home/tlamadon/git/econ-21340
Computing Pi by numerical integration
Our goal is simply to compute an approximation to the constant \pi. We are going to do this in a very very crude way. You can read more about computing approximation to the constant here
We are going to use the fact that the area under a circle with unit radius is equal to \pi. Hence we can simply partitioned the unit square of [0,1] x [0,1] into small squares and computer the area covered by squares that are inside the circle. This will give us an approximation to the constant.
So, I ask you to simlpy write a function that takes a number n which is the number of blocks in which to split the x and y coordinates of the unit square (ie we have n^2 little squares).
This function should then return the area covered by small squares that are fully included under the unit circle, as well as the area covered by small squares fully covered as well as partially covered. The first number should be lower bound on \pi and the second number should be an upper bound. You need to multiply your number by 4 since we are focusing on the top right quadrant.
You can implement this function by computing a naive double for loop. We are simpy trying to get acquainted with python at this point. As a matter of fact, this could be implemented without numpy.
Here is the outcome of the function I wrote:
solution.compute_pi(1000)
(3.137524, 3.14552)
We can compare this values to the value of \pi
np.pi
3.141592653589793
Run several times
Do this for values of n between 10 and 1000 with steps of 100. Construct your response using python list comprehension. Store the vector of values in N and the results in R.
N,R = solution.repeat_pi()
R
array([[2.76 , 3.44 ],
[3.10247934, 3.17421488],
[3.12163265, 3.15945578],
[3.12853278, 3.15421436],
[3.13135039, 3.15083879],
[3.13347174, 3.14914264],
[3.13465198, 3.14773448],
[3.13582226, 3.14708193],
[3.13659503, 3.14645328],
[3.13702693, 3.14581331]])
Next we import matplotlib and plot our results. We plot both bounds.
import matplotlib.pyplot as plt
plt.plot(N.T,R)
plt.xlabel("log n")
plt.ylabel("bounds")
plt.show()
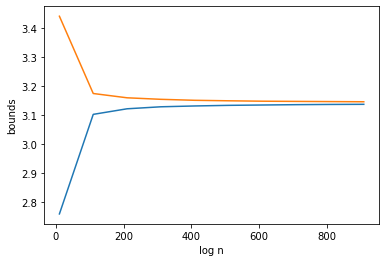
Use matplotlib to plot the log distance between the 2 bounds versus the log of n. Given your results, and assuming linearity in this representation, how large would n have to be to get to the precision listed in the article linked at the begining? Given how long your function is taking, how much time would that be using this crude approach?
solution.plot_pi(N,R)

Use draws instead
As we all know, an expectation is an integral, and an area is also an integral. Instead of cutting out the unit square inm smaller square, we can simply draw points uniformaly.
Express a G(x,y) function wich is 1 if x,y is in the unit circle and 0 otherwise. Then if we draw x and y from the unit square as before we should get that:
Draw n uniform x and y using the right function from numpy.random and compute the expecation over your draws. Compare this value to \pi.
pi_hat = solution.sim_pi(100000)
pi_hat
3.14016